Related: rust, systems-programming
Use Light Mode for the best reading experience
The images here aren’t optimized for Dark Mode. I haven’t figured out a way to make them adaptive. If you know how, do let me know!
I love optimizing code—there’s something gratifying in cleaving away massive inefficiencies instead of “throwing more compute at it”. It’s a waste of resources and carbon emissions!1
In my work, I’ve optimized the memory usage of Python dataframes a number of times. Often the quickest solution, without additional context, is simply to perform type downcasting—e.g. convert a int column of zeros and ones to bool. While this works, more recently I am quite surprised to learn that booleans are not always represented as single bits! So how exactly do types get mapped to bits and bytes in memory?
Just like how you want a neatly organized library of books to get the information you need easily, the way data is stored in memory can have significant implications on your application’s performance, memory efficiency and correctness.
This is a two-part series on memory representation of data in applications.
In this first article, we’ll explore:
- what is alignment and why it is crucial
- what is memory layout and some example representations
- how to estimate the memory footprint for builtin and custom types (in Rust)
- various surprises depending on your previous mental model. Like me, you might be surprised to learn that a boolean doesn’t always take up one bit of memory!
With that, let’s take a deep dive into how data is represented in memory—one byte at a time! 🤿
Scope: Memory layout for statically-typed languages
I’m covering how types are represented in statically-typed languages like Rust, as part of my readings on Rust for Rustaceans. Dynamically-typed languages have additional complexities that are built on ideas in this article, that I might cover at a later point in time.
How bytes in memory are interpreted?
Computers store data as a sequence of bits in memory. However, bits on their own do not have any inherent meaning. A type is what a program uses to interpret these bits into something semantically useful to the programmer.
Note
A program uses types to interpret bits in memory.
For example, the bits 10100011 can be interpreted as 163 as an unsigned integer or -35 as a signed integer.
The concept of alignment
Alignment refers to how bits are placed in memory. In theory, it shouldn’t matter where a sequence of bits are placed in memory as long as those bits are contiguous and in the correct order.
However, in practice, the hardware enforces some rules on how data is read and written into memory, making alignment pertinent. To start, pointers always point to bytes and not arbitrary bits—a pointer allows you to refer to byte N or N+1, but not any bit in between the two.2 Data that starts at the byte boundary is called byte-aligned.
An additional rule is that most computers read data in chunks, a.k.a word—the number of bits a CPU can process in a single instruction. You might have heard that your device having a 64-bit architecture,3 which means that its memory address is 64-bits wide and it reads data in 64-bit chunks.

Impact of misaligned data
Imagine we have a variable of type i64 (8-bytes). When its underlying data is aligned, the computer reads the bits in the first 64-bit chunk (green row below) to interpret the value of that i64 type. This is done using a single read operation.
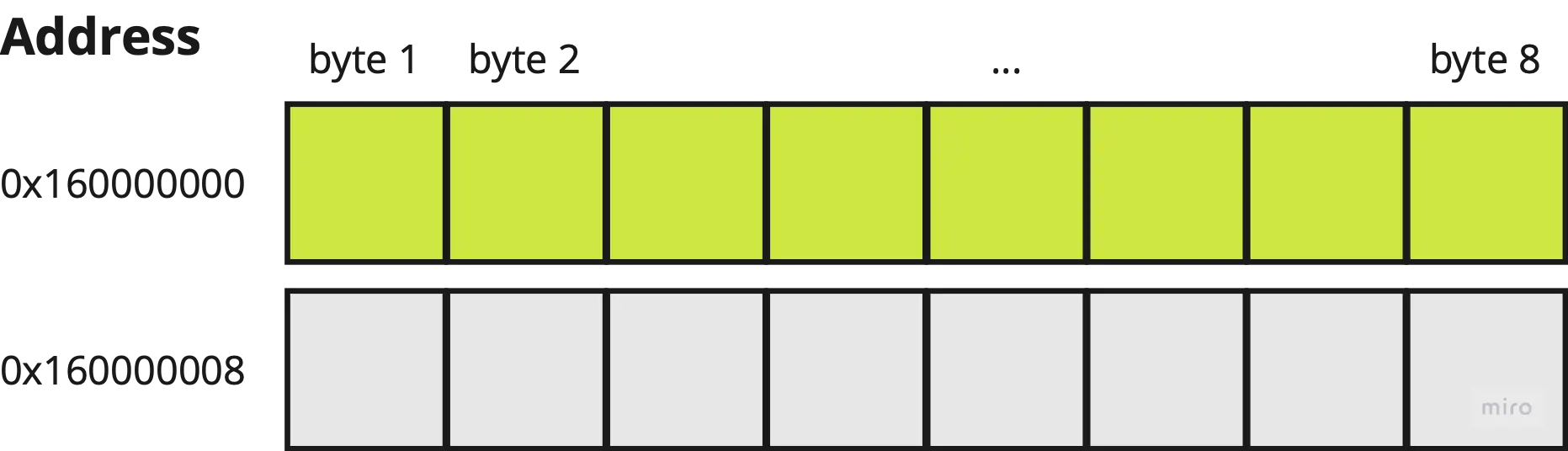
So what if the data is misaligned, as shown below?
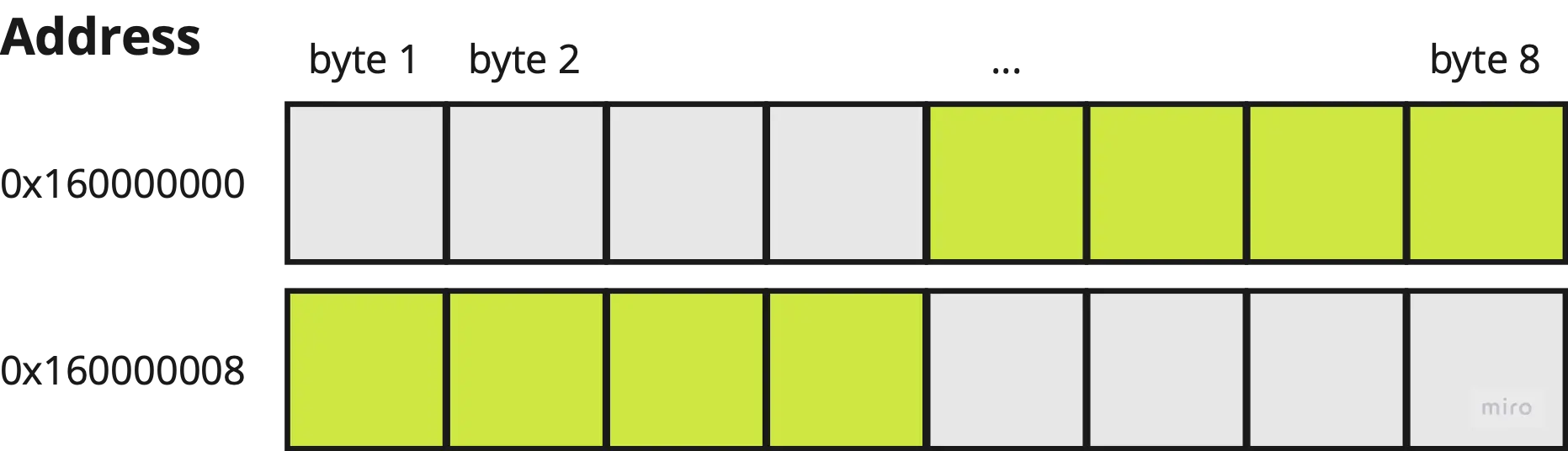
To interpret this value,
- the bits at the first word (chunk) is read
- the first half of the bits are masked out and the second half kept
- the bits at the second word is read
- the second half of these bits are masked out, and the first half are kept
- the bits from steps 2 and 4 are appended together
As we can see above, this takes significantly more operations leading to worse read/write performance in your application.4 Furthermore, there is a risk of data corruption in concurrent applications, if data at the second address is modified (by a concurrently thread) while the first address is read.
In the example above, we can see how alignment forms the basis of not only performant, but also sound applications.
Power-of-two alignments
Most fundamental, builtin data types are “natively”-aligned to their size. A u8 is byte-aligned, an i16 is 2-byte aligned, a u32 is 4-byte aligned and an f64 is 8-byte aligned. Notice that they are in powers of two, and this is not a coincidence. Many modern computers use a power-of-two alignment for performance optimizations.
If the address of a data mod n is 0, then the data is n-byte aligned. So, a u32 type is considered aligned if its data start from the first or the fifth byte of a word.[^8] At every other starting byte within the word, the u32 data is not aligned.
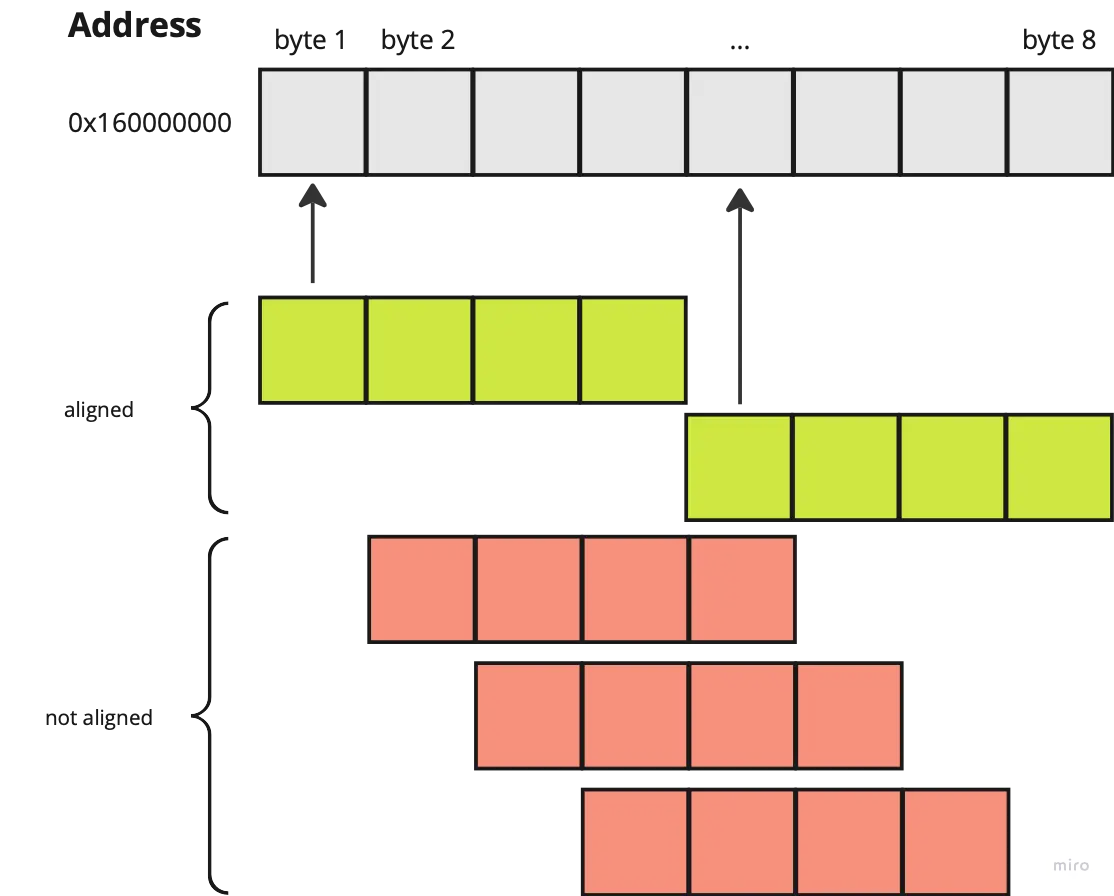
u32 as an example)Layout for optimal memory footprint
While alignment relates to how bits are organized relative to byte boundaries in memory, memory layout refers to how data for different fields are arranged within a type.
Using Tetris as an analogy, a block can only be aligned at specific positions on the grid. Meanwhile, how different blocks are arranged relative to each other is the layout.
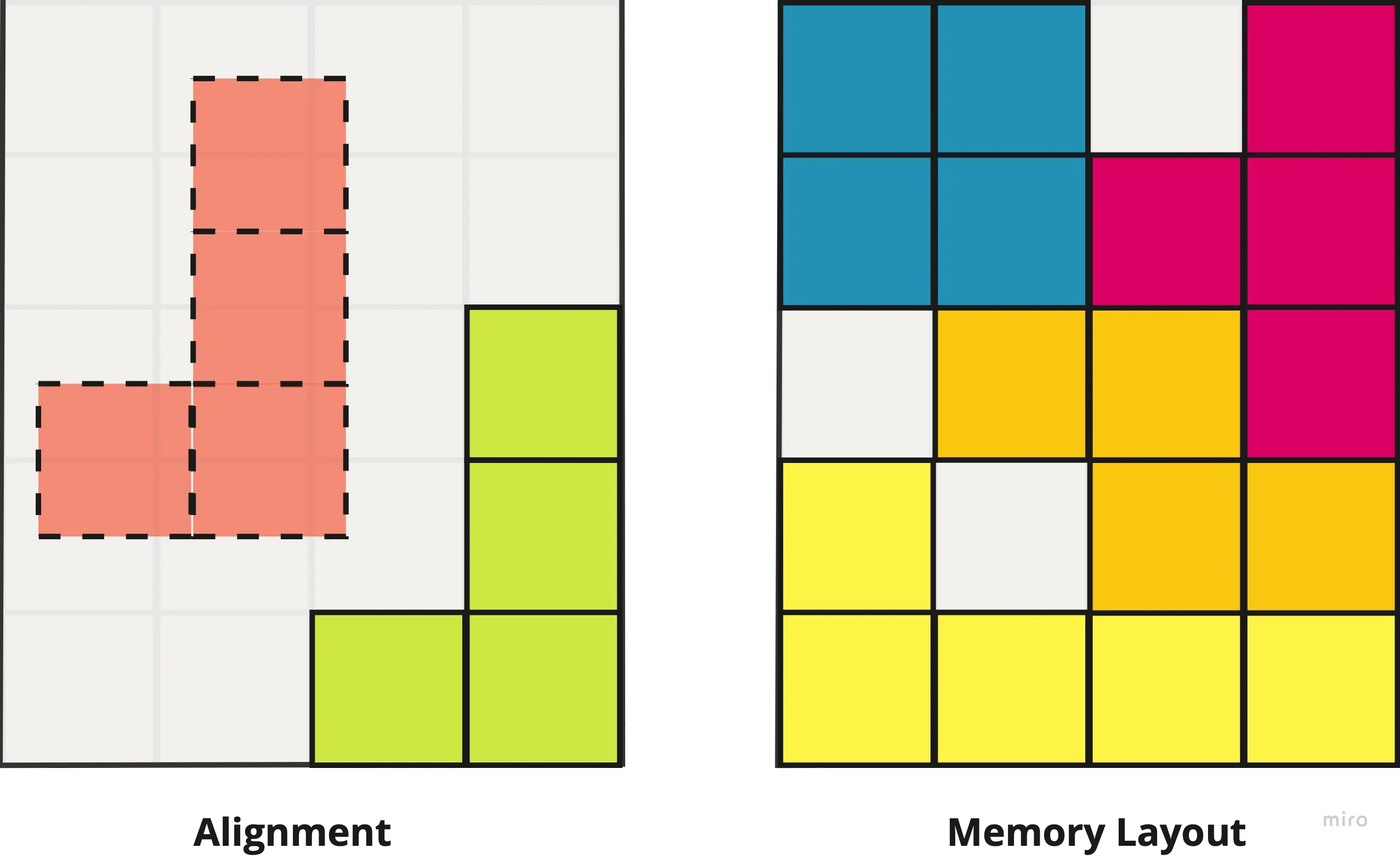
As we’ll see below, the way memory is represented impacts a type’s memory footprint and that of the overall application.
Memory layout for a struct
Let’s say we have struct holding various fields as follows:
#[repr(C)]
struct Foo {
tiny: bool,
normal: u32,
small: u8,
long: u64,
short: u16,
}The compiler needs to decide the memory layout of the Foo struct—how the different fields’ data are arranged within the struct.
There are a few rules the compiler use to decide this:
- Bits must be byte-aligned
- Built-in datatypes are “natively”-aligned to their size (a
u16is 2-byte aligned; anf64is 8-byte aligned as discussed previously) - Complex types that are made up of other types have alignments equal to the largest alignment of its component types
To start off, we will be looking at how the Foo struct above is aligned using a C-style memory representation, as configured by the #[repr(C)] attribute. Later, we’ll compare how the memory layout of Foo differs with a Rust-style representation.
This is out the fields of Foo are laid out, in C:
tinyis a boolean, so intuitively it should only occupy one bit, right? Actually, no 😮 It occupies 1 byte (8 bits) of memory, because of the first rule. If it were to be just one bit long, subsequent appended data would not be byte-aligned.5normaltakes up 4 bytes and is 4-byte aligned due to the second rule. So, we cannot immediately append it totiny’s data. Instead, we first need to append three bytes of padding. This brings the memory usage so far to 1 + 3 + 4 = 8 bytes.smalltakes up one byte and is byte-aligned so it can be appended directly.longoccupies 8 bytes, and is 8-byte aligned. Since the memory usage up to this point is 1 + 3 + 4 + 1 = 9 bytes, 7 bytes of padding needs to be added to ensure thatlong’s data is 8-byte aligned (i.e. starts at the 16th byte)shorttakes up 2 bytes and can be directly appended to the sequence of bits.
Up until this point, the memory usage is (1 + 3) + 4 + (1 + 7) + 8 + 2 = 26 bytes.
Finally, the Foo struct itself also has to be aligned. This is needed so that the data that comes after a Foo instance still falls within alignment boundaries. From the third rule, Foo takes on the alignment of its largest field long, so it itself is 8-byte aligned. As such, 6 bytes of padding is added at the end to “round up” the memory layout from 26 to 32 bytes.
Below is a visualization of the final result.
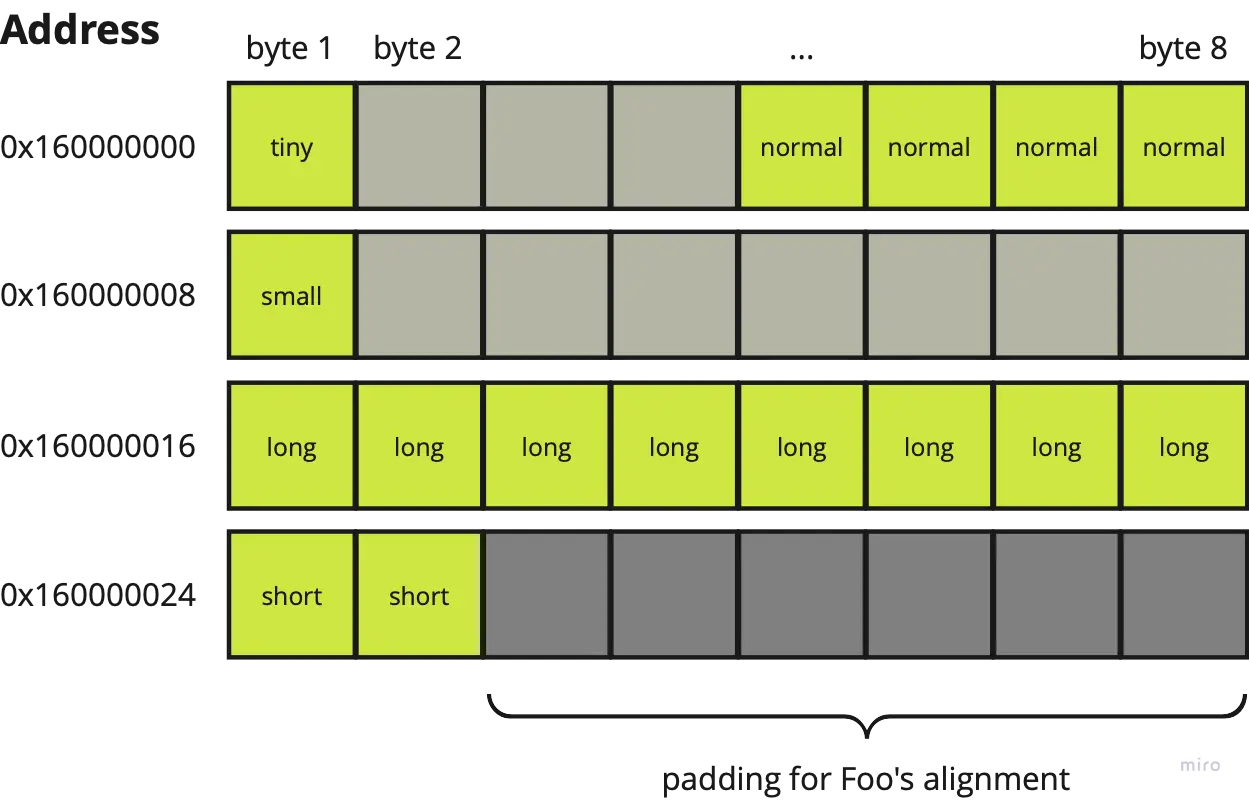
Foo structVerifying size and alignment programmatically, in Rust
At this point, you might be wondering how you can verify the claim above, or any data type for that matter.
In Rust, you can do so with the
std::alloc::Layoutstruct.For convenience, here’s the runnable code snippet from the Rust Playground:
Rust-style memory layout
As we just saw, the C-style representation requires all fields to be laid out in the same order as they were defined, leading to a predictable albeit suboptimal memory layout.
Meanwhile, Rust’s default memory representation (#[repr(Rust)]) does not have such strict guarantees, allowing for the Rust compiler to optimize the layout to be more compact and efficient. It does this by laying out memory in decreasing order of field size.
#[repr(Rust)] // Omitting this line has the same effect
struct Foo {
tiny: bool,
normal: u32,
small: u8,
long: u64,
short: u16,
}Below is how Foo’s memory layout looks like with a Rust representation:
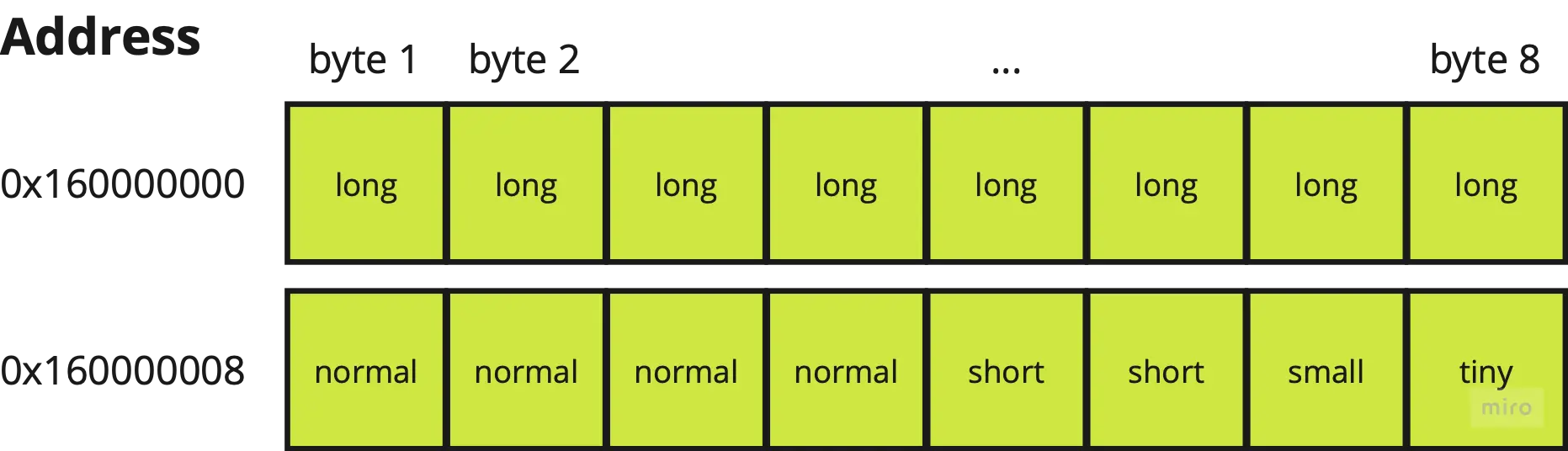
Foo structAs you can see, this is significantly more memory efficient—half the memory footprint is required compared to the C-style memory layout!
Reasoning memory layout for common types
Now that we’ve learnt how memory is laid out for a custom type, how does the memory layout look like for common builtin types, specifically tuples, enums and arrays?
Tuples
For tuples, the values are represented like structs fields defined in the same order. This means that Foo and a (bool, u32, u8, u64, u16) tuple would occupy the same memory layout.6
Enums
The memory layout of enums consist of two parts—the discriminator and the enum variant. The discriminator value represents the index of the variant—in practice, 1-byte long.7 Each variants’ layouts are determined independently. The enum’s variant memory is the size of its largest variant , and the enum’s discriminator alignment follows the largest variant’s alignment.
For example, the Shape enum below:
enum Shape {
Circle { radius: f32 },
Rectangle { width: f32, height: f32 },
Square(f32),
}has the following memory layout:
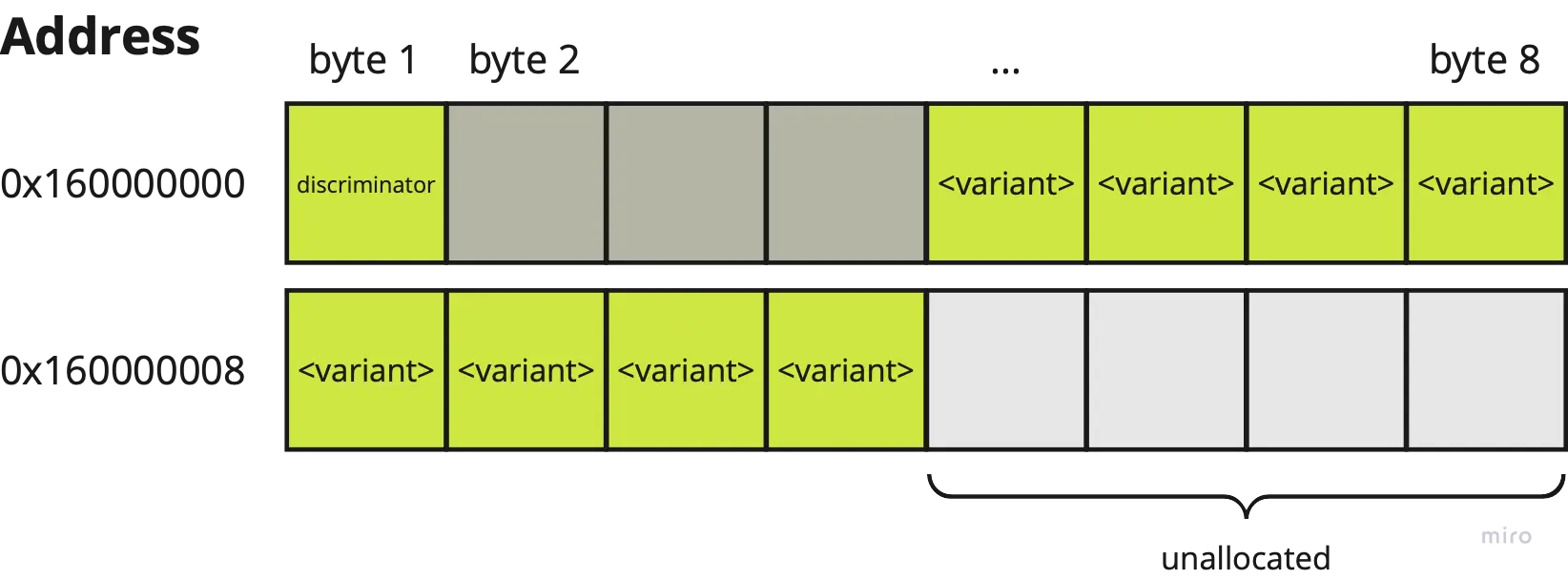
Shape enumEach variant’s memory layout is computed independently:
Shape Variant | Size (bytes) | Alignment |
|---|---|---|
Circle | 4 | 4-byte |
Rectangle | 8 | 4-byte (Its largest field is 4-byte aligned) |
Square | 4 | 4-byte |
The variant part of the enum’s memory layout would be 8-bytes long. This is to accommodate any possible concrete variant.
The discriminator would be u8 to represent the three possible values this variant can take. Even though u8 is byte-aligned, it has to follow the largest alignment of the variant (4 bytes). So, 3 bytes of padding is appended to the discriminator.
Arrays
Arrays are represented as a contiguous sequence with no padding between its elements.
An array of the Shape enum above would have the following memory layout:
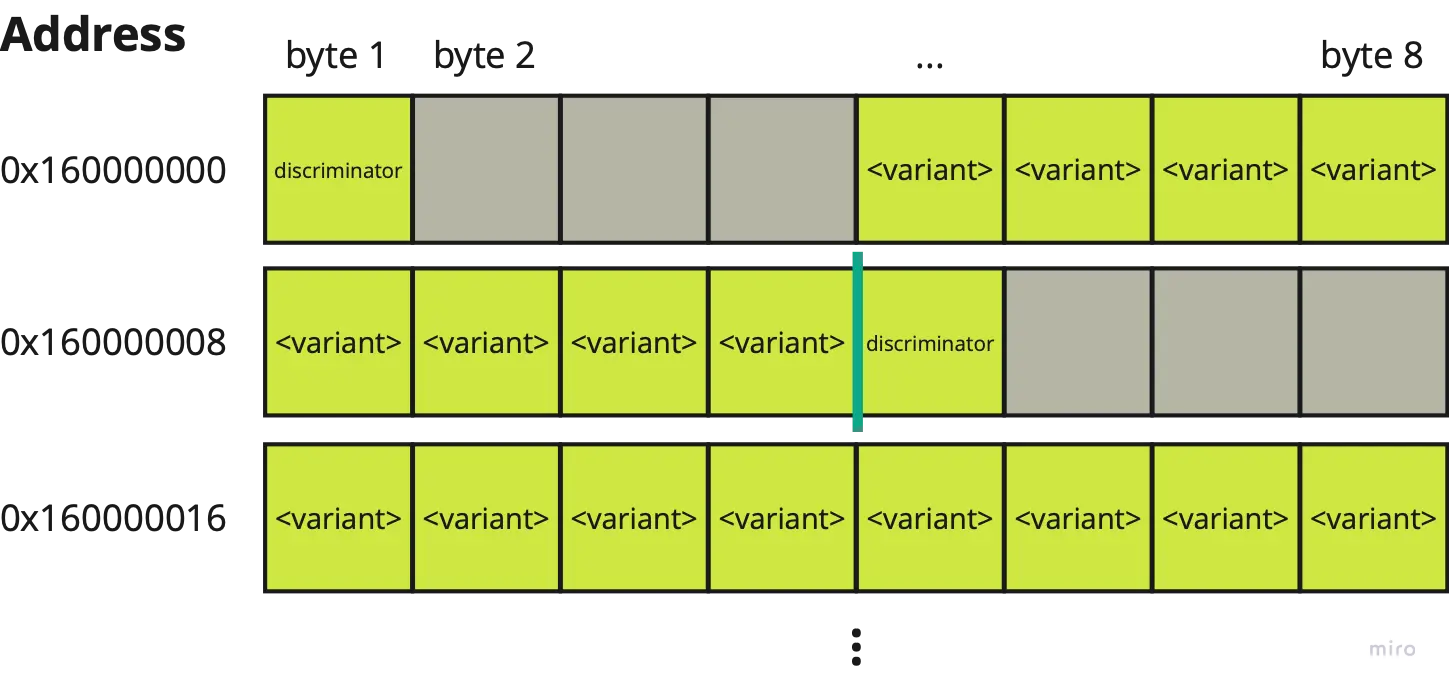
Shape enums.Subsequent elements are immediately placed without padding (dark green line).
Practice Exercises
Interested in testing your newfound understanding of memory layout on more examples? Check out some more practice exercises.
Conclusion
By now, you should have a better mental model of the concept of alignment and memory layout. You should have a better intuition on how memory is laid out for different types in your program.
From the examples above, we can see how the memory layout has a big influence on your type’s memory footprint and the application’s memory footprint as a whole. An inefficient memory representation can bloat up your program really quickly, especially when there are many instances of a type, e.g. in an array.
However, you may not always want your memory representation to be as compact as possible. As with many things in engineering, there are tradeoffs.
In the follow-up article to this, we’ll see what other memory representations are available (in Rust), when to use them, and why you may not always want the most efficient memory layout for your types.
Footnotes
-
Of course, optimization must be done within the context of business priorities, project timelines and how often a code will run—not every nook and cranny needs to be optimized. ↩
-
As a result, even a boolean which should only require a single bit, takes up a whole byte (8 bits)! You can, however, use
bitfieldencoding to make it more compact. ↩ -
That’s the “64” in
x86-64or ARM64. ↩ -
This is a simplification. In reality, data is read from memory to the CPU cache in cache lines of 64 bytes. That’s 8 times larger than the 64-bit word size of most modern computers. So, more accurately, data that is misaligned at the cache lines will incur this penalty. ↩
-
Another way to think about it is that a boolean takes up 1 bit, with 7 bits of padding. ↩
-
Other than ordering data from largest to smallest, the Rust compiler does not guarantee the ordering of equally-sized fields. ↩
-
If you have more than enum variants in your application, I think an application design review is in order… ↩