Question
Where does the raw data reside and how to we extract it?
There are three different modes:
Databases
Process A writes into DB which process B reads from.
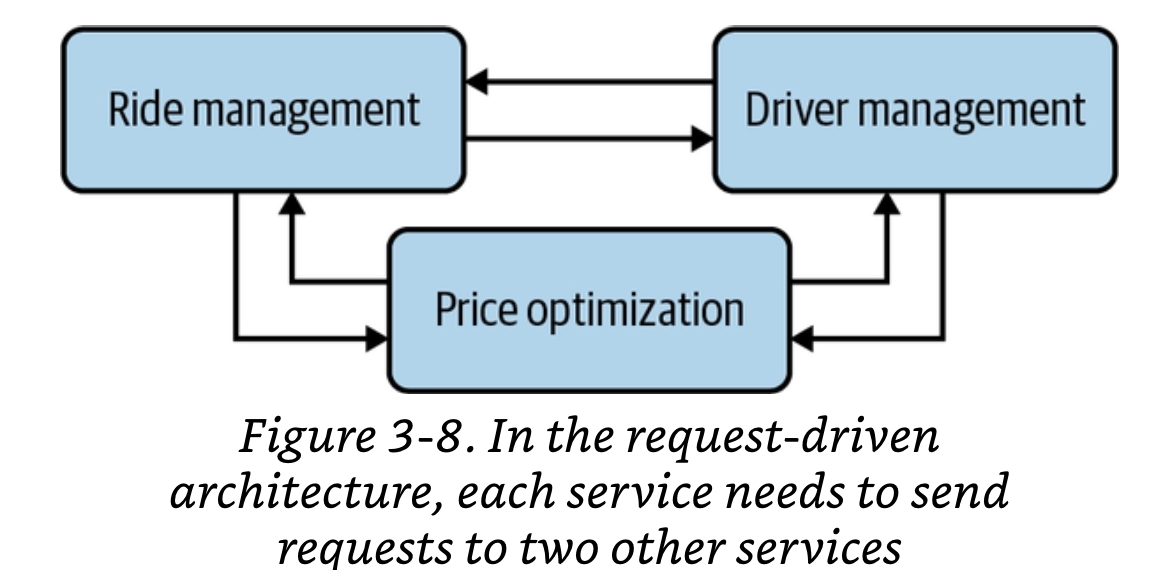
Services
Process A requests data from process B using an API like REST or RPC.
Real-time transport
Different processes get data from other processes through an in-memory storage as the data broker.
Comparisons
| Type | Architecture / Use Case | Pros | Cons |
|---|---|---|---|
| - Batch | Simple | - Not all processes have access to the same databases (e.g. processes from different organizations) - Read/writing from the same database can be slow | |
| - Service-oriented architecture - Request-driven - Microservices - Batch(?) | - Different processes from different organizations can access the data - Allows services to be decoupled | As the number of services, and those that depend on each other, scale: - Inter-service data passing becomes the bottleneck, as the same data is sent to the requestor redundantly - Cascading failures when services go down | |
| - Event-driven - Streaming | Addresses shortcomings of services. | - More complex |
{kind=link}