Why is CUDA the way it is?
Physics—the rules that govern how GPU hardware are operate
Techniques to GPU performance
GPU performance is almost always limited by memory bandwidth.
In an NVIDIA Ampere GPU,
Memory bandwidth improvements hasn’t kept up FLOPs improvements.
As such, the techniques below maximize memory bandwidth usage:
- Optimal memory access patterns (up to 13x)
- Occupancy (up to 2x)
- Concurrency
Fundamentals
How data is read in a GPU
Data in a GPU is stored in a 2D matrix of capacitors. It is stored as a matrix to allow for random access.
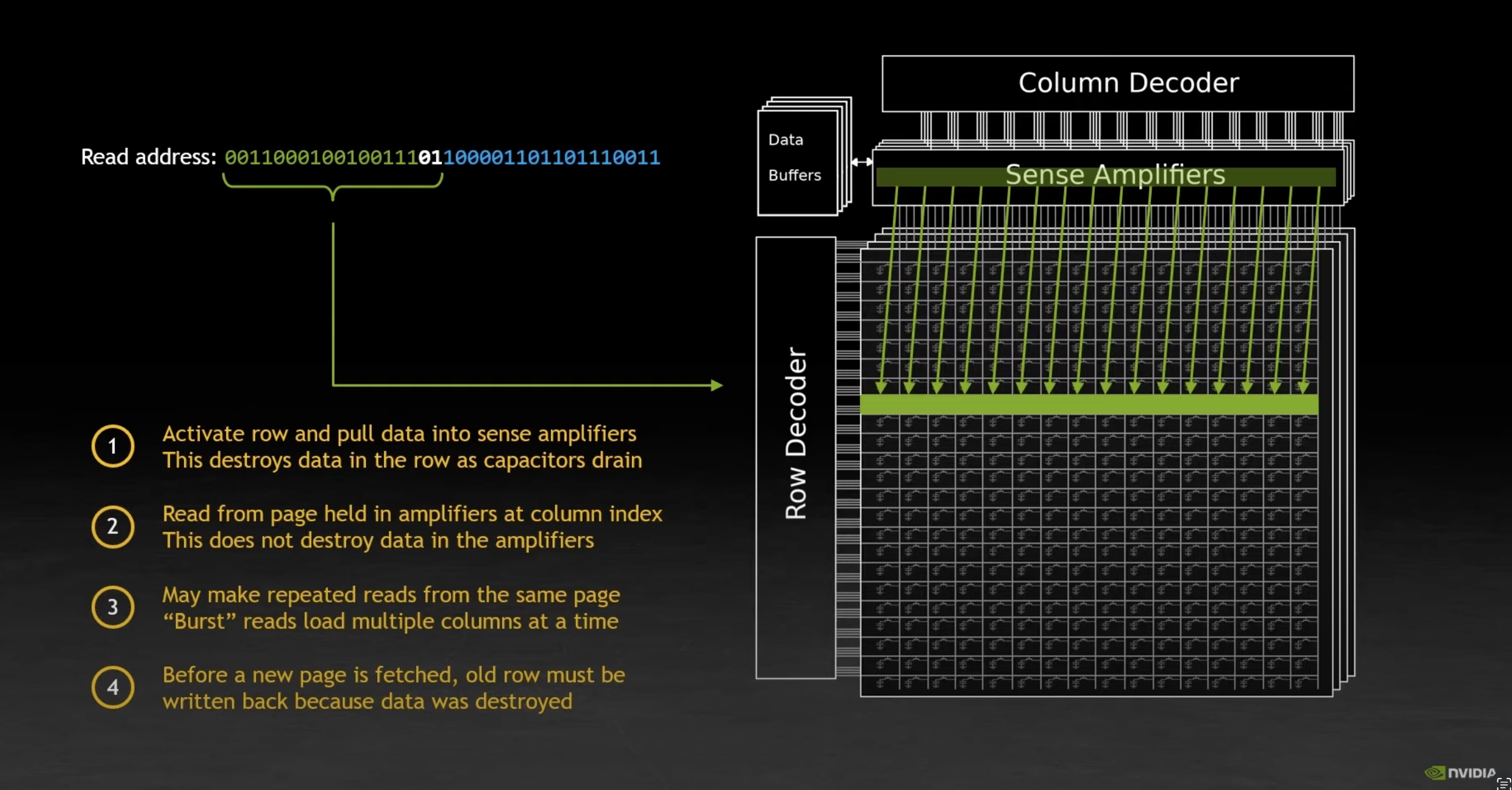
The Sense Amplifier holds data persistently, so data can be read repeatedly without being destroyed.
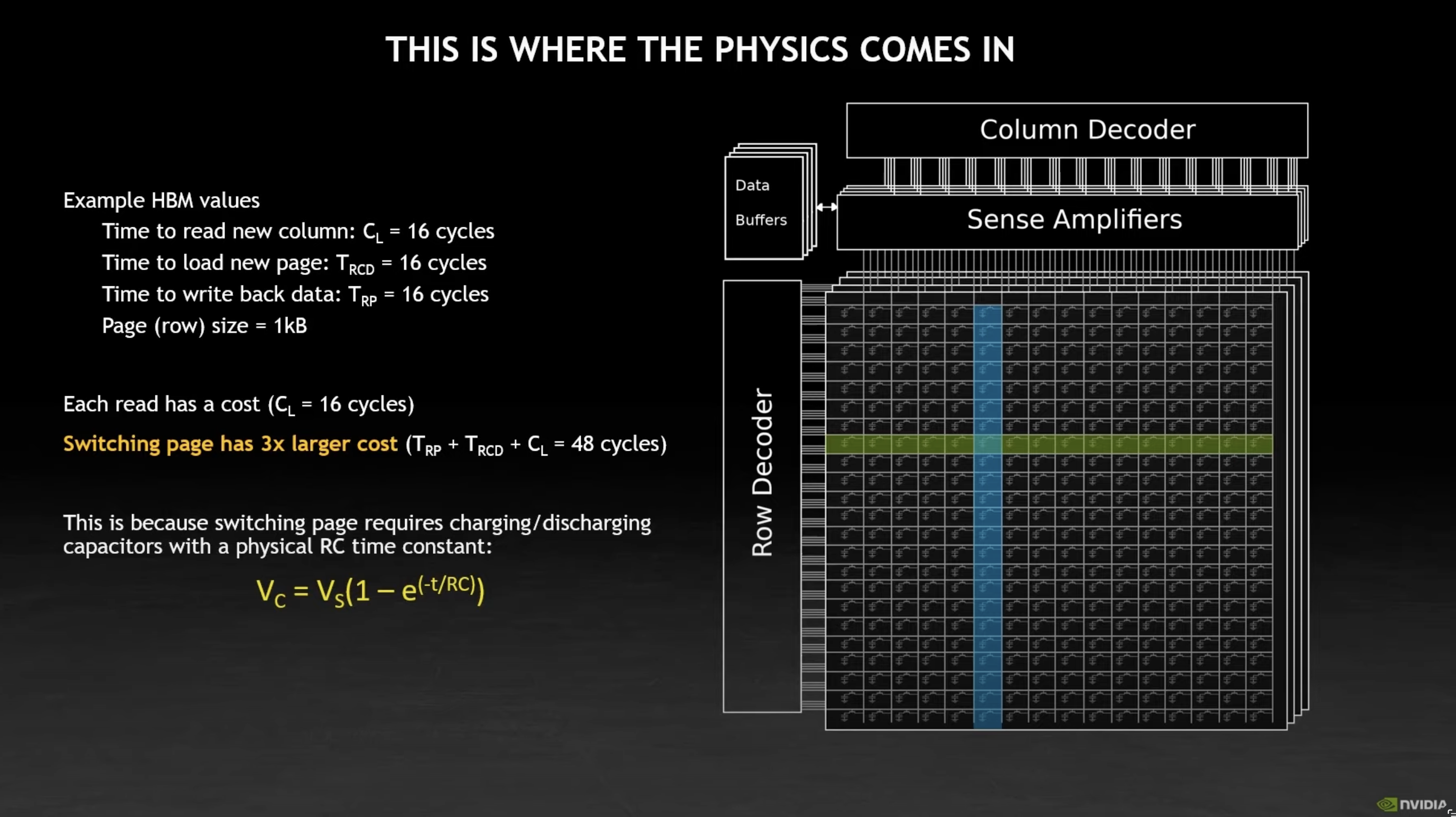
Cost of switching pages
Switching pages (rows) is 3x more expensive
So avoid switching pages, or accessing data randomly as much as possible!
It is expensive as we need to write back data from the Sense Amplifier to the row that was drained, before loading in data in from another row to the Sense Amplifier.
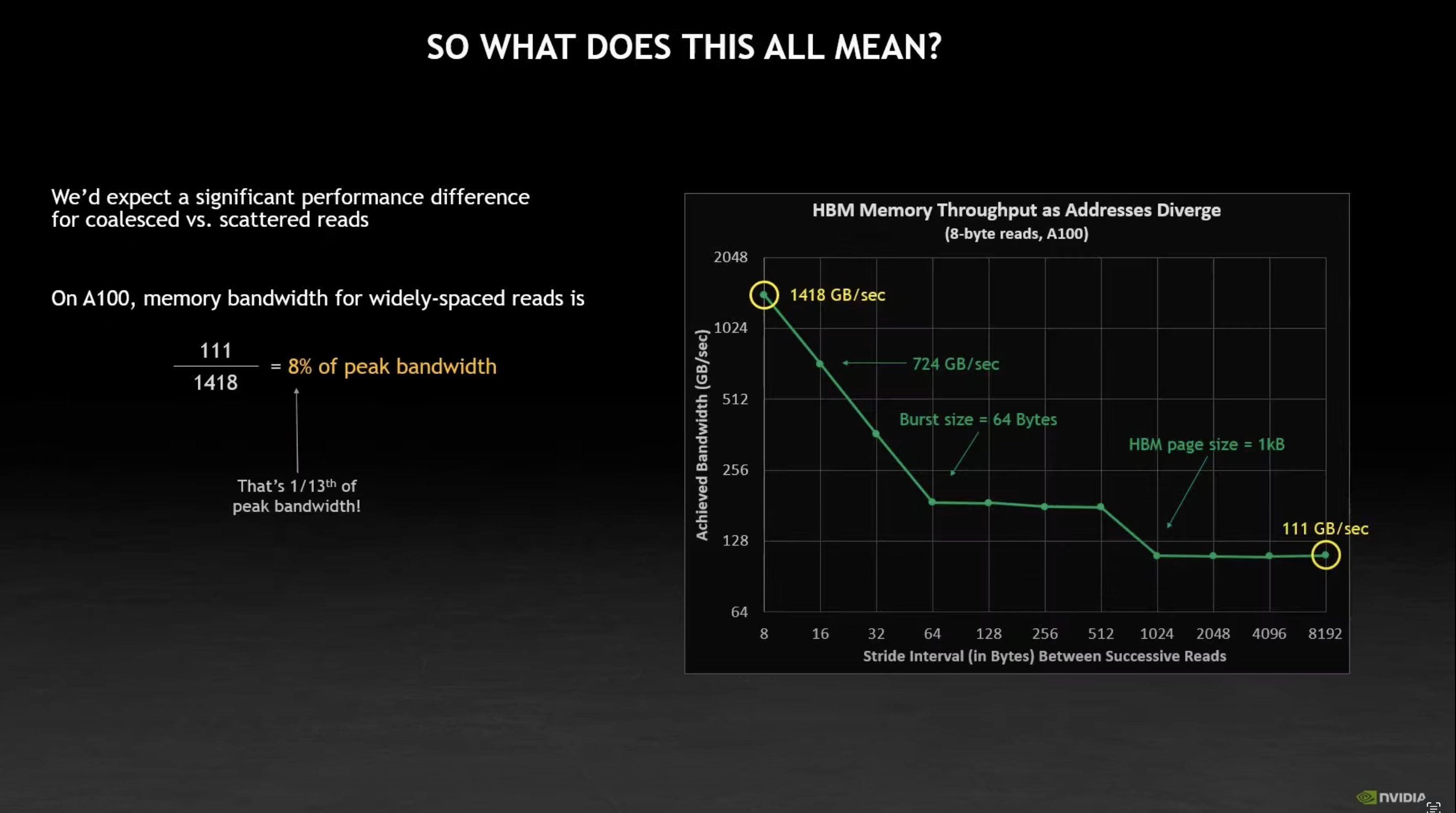
Row Major vs Column Major Access Patterns
Row-major reads (i.e. read data column by column within a row) can be up to 12.5x faster than column-major reads.
GPU Execution Hierarchy

Block
This is the atomic unit of parallelism within a GPU.
A block consists of threads. Within a block, these threads are subdivided into groups of 32 threads known as a warp.
The number of threads in a block is configurable by the kernel programmer. What then, is the optimal thread size? See … todo
Minimum block size
A block should always have at least 128 threads. This is because with 32 threads per warp, and 4 SPs per SM. This allows you get to optimally read all the data in a page before moving on to the next page.
#todo Generalize this point to any (NVIDIA) GPU
Warp
A group of threads within a block. Each wrap contains 32 threads.1
Warps is a thing as an SM can only operate on 42 warps at a time.
Stream Multiprocessor (SM)
This is the hardware that executes the computation, analogous to a CPU core.
Within it are stream processors (SPs). Each stream processor operates on a warp.
How does the GPU executes work in parallel?
- The work itself is divided into blocks, which can be operated in parallel
- Each block’s threads are loaded into the GPU’s SMs3
- The SPs within the SM processes the block’s warps concurrently
The CUDA programming model
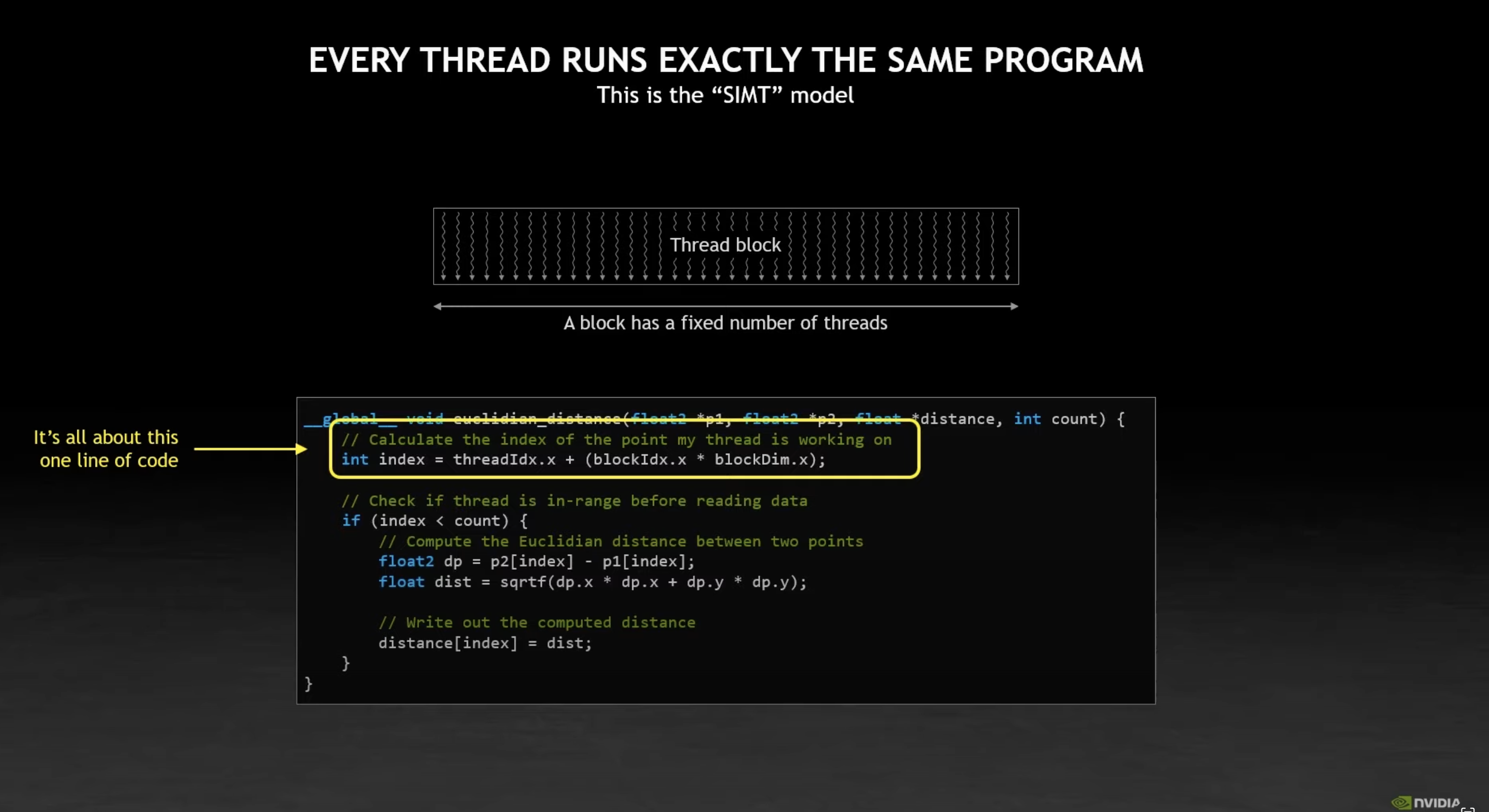
CUDA uses a SIMT programming model.
The SIMT programming model
All threads perform the same operation, on slightly different data addressed by a specific index.
In this model, you write the core logic of your program by thinking in terms of the operation each thread will perform.
SIMD vs SIMT
In SIMD, a single thread operates on a vector unit. You have explicit control on how a single thread operates over this entire vector.
In SIMT, threads all operate independently of one another, with each thread having its own state. Each thread can do its own custom computation with (loops, conditionals etc). However, the overall operation would be more efficient if all threads can finish the work at the same time.
| SIMD | SIMT | |
|---|---|---|
| Acting on | Vector unit | Thread |
| Thread control | Explicit | Implicit |
Contextual Variables in a CUDA function
A CUDA function has a few contextual (environment-like) variables. These are defined implicitly, with unique values for each thread.
Examples include: threadIdx, blockIdx and blockDim.
These variables are used to uniquely identify the index of data each thread is operating on.
The index itself is guaranteed to be consecutive.
Terminology
| Abbreviation | Meaning |
|---|---|
| HBM | High-bandwidth memory |
| SM | Stream multiprocessor |
| SIMD | Single-instruction multiple data |
| SIMT | Single-instruction multiple thread |
References
https://www.youtube.com/watch?v=QQceTDjA4f4
Footnotes
-
This is by design. One of the reasons if that it makes seemingly random memory access not that random after all. ↩
-
This is likely a parameter specific to A100 GPUs in the example. I believe this is known as the number of Stream Processors (SP) per Stream Multiprocessor (SM). ↩
-
Sequential blocks tend to be spread out across multiple SMs instead of the same SM, in order to process work as concurrently as possible. This is because each SM has a load bandwidth (GB/sec), so loading sequential blocks into the same SM means that other SMs will be left idle. ↩