Definition
How many blocks of work can you pack onto an SM
This is a concept that is the most powerful tool for tuning your GPU program.1
Footprint of a block
Each block has its own “footprint” which comprises of the following components:
| Component | Description |
|---|---|
| Block size | The number of threads in the block to run |
| Shared memory | Shared by all |
| Total2 number of registers | Working space for a thread,3 and a per-thread resource.4 The number of registers is based on the program’s complexity5 and is determined by the CUDA compiler. |
Budget of an SM
There is a “budget” that limits how many blocks you can fit to an SM:
- Threads per SM
- Total registers per SM
- Total shared memory in SM
Max blocks per SM6
How are blocks placed into the SM?
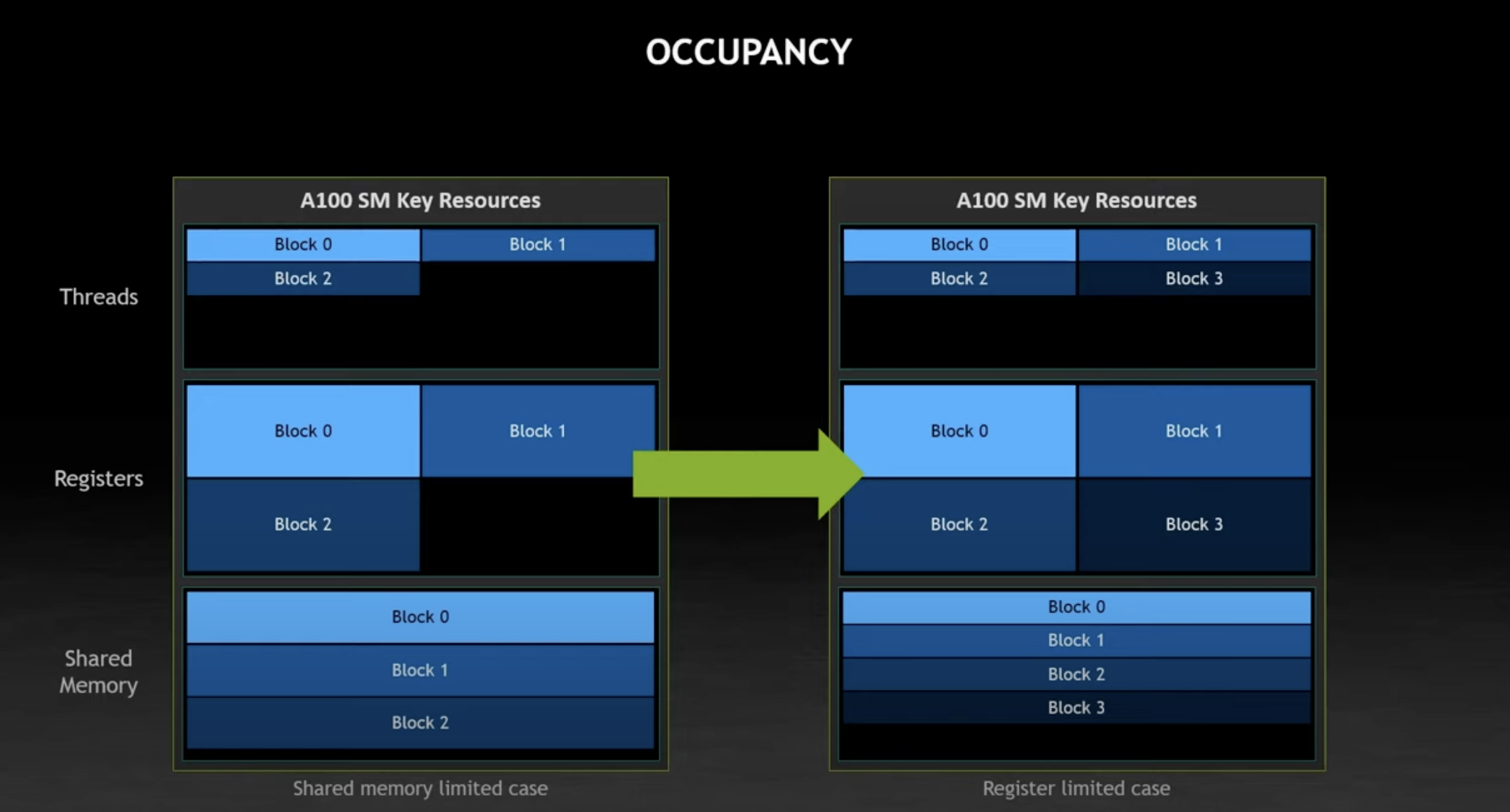
By optimizing the footprint of your block, you can increase the number of blocks you fit into the program.
A fundamental assumption in this is:
NOTE
A block never spans multiple SMs.
Footnotes
-
CUDA architect Stephen Jones starts with this in mind before designing his programs. ↩
-
Registers/thread x Threads/block ↩
-
Akin to RAM. Unlike CPUs, this “RAM” is not relying on cache, but actual registers. They allow direct access to data since memory performance is so critical for GPUs. ↩
-
A hundred registers per thread is rather common for a CUDA program ↩
-
For example, multiply and division operations need a lot of working space, so they take up more registers than simpler operations ↩
-
Rarely reached, so can be mostly ignored ↩